
Pues bien nos encontramos con el siguiente escenario: 4 nodos de Jboss en clúster como backend y por otro lado, un servidor frontal inicial de Apache que redirecciona y balancea a esos backends. La cuestión es, si se cae ese servidor frontal Apache el resto de la infraestructura quedará inaccesible. Lo ideal sería que si cae el frontal, existiera otro servidor de respaldo que retomara las funciones para no interrumpir el servicio de cara al cliente:
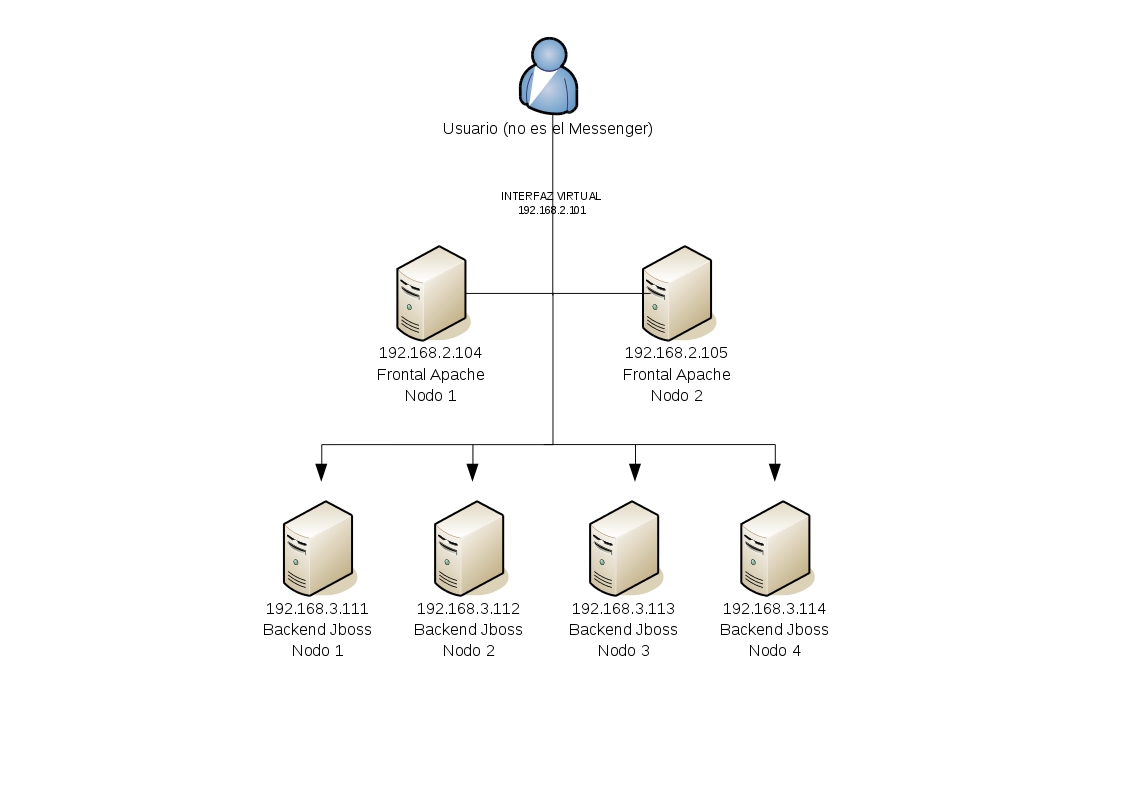
Entorno Apache + Jboss en alta disponibilidad
Para evitar esta situación viene a nuestra ayuda Pacemaker/Corosync, que permite crear clústers de alta disponibilidad de recursos. También existen otras herramientas como por ejemplo Heartbeat que serviría para tal menester, pero es un proyecto más antiguo y tiene más limitiaciones.
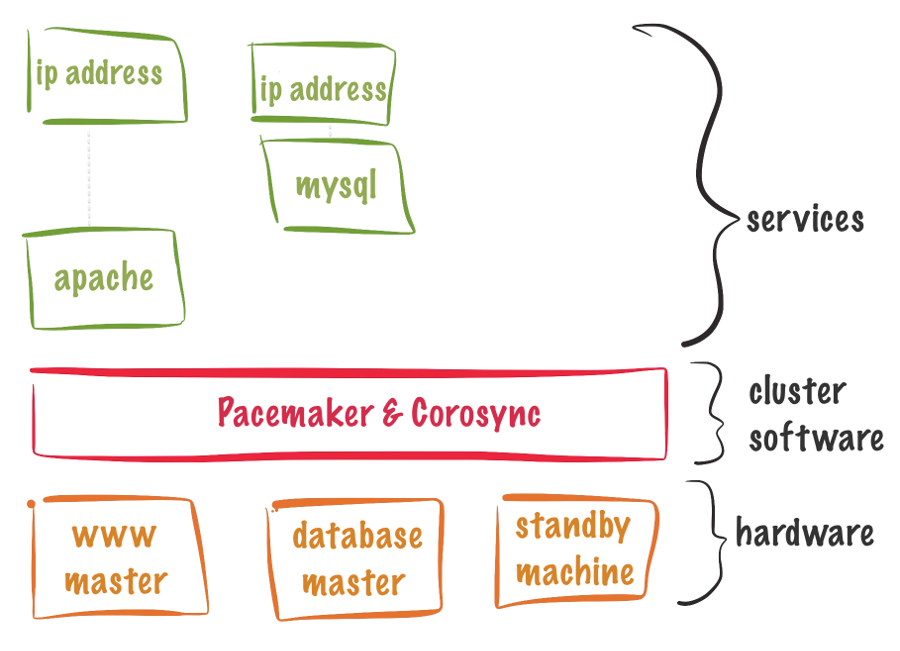
Alta disponibilidad con Pacemaker
En este caso utilizaré Ubuntu Server LTS 14.04. Para otras distros Linux el procedimiento (cambiando gestores de paquetes y configuración de red) es similar, por lo que también os servirá esta guía.
Instalando y preparación inicial de Pacemaker/Corosync
Este paso no tiene pérdida, en cada uno de los nodos hacemos:
apt-get install pacemaker corosync apache2
También puedes descargarte el código fuente de Pacemaker repositorio de GitHub y compilarlo tú mismo aunque te recomiendo que utilices un gestor de paquetes como apt-get o aptitude por la cantidad de dependencias que tiene, que también tendrás que resolver a pelo si compilas desde código fuente… De todas formas en la propia página de GitHub tienes las dependencias e instrucciones a seguir.
Cada nodo deberá compartir la misma clave de autenticación para poder formar parte del clúster. Es una medida de seguridad básica. De no ser así, descubierto el servicio de clúster no sería demasiado difícil comenzar a añadir nodos al clúster con fines maliciosos.
En el nodo 1 creamos la clave:
corosync-keygen
Y la copiamos al nodo 2:
scp /etc/corosync/authkey 192.168.2.105:/etc/corosync/authkey
En ambos nodos, le damos permisos a la clave (no iniciará si no le damos estos permisos bastante estrictos):
chmod 400 /etc/corosync/authkey
También en ambos nodos tendremos que especificar la red en la que se va a escuchar el heartbeat de Pacemaker. Esto se hace en /etc/corosync/corosync.conf:
bindnetaddr: 192.168.2.0
Veréis que la red de los nodos de Jboss es 192.168.3.0. Esto se debe a que es mejor que los frontales en alta disponibilidad tengan su propio segmento de red, separado del resto. Al fin y al cabo los mensajes de hearbeat (latido) para determinar el estado del clúster es mejor que vayan por una interfaz y red dedicadas exlusivamente a tal fin (es simplemente una cuestión organizativa, si lo haces de otra manera también te va a funcionar).
Reiniciamos el proceso de clúster en ambos nodos:
service corosync restart
Por otro lado, si queremos que el servicio de corosync se inicie al arrancar el sistema, en /etc/default/corosync ponemos el START en yes:
START=yes
Configuración de la interfaz virtual de red para alta disponibilidad
Esta parte es interesante. Por defecto cada servidor tendrá, como suele ser común, una NIC física, una interfaz de red. Para el nodo 1 será la IP 192.168.2.104. Para el nodo 2, la 192.168.2.105. Ahora bien, tendremos que crear una interfaz virtual con IP 192.168.2.101 que será la que realmente reciba las peticiones del cliente.
¿Cómo hacemos esto? En el fichero /etc/network/interfaces de ambos nodos añadimos la interfaz virtual eth2:0:
manual eth2:0
iface eth2:0 inet static
address 192.168.2.101
netmask 255.255.255.0
Configuración de recursos en alta disponibilidad en Pacemaker/Corosync
Interfaz virtual en alta disponibilidad
De lo que se trata es de lo siguiente: supongamos que el nodo 1 de Apache es el que está prestando servicio y cae por la razón que sea. El nodo 2 tendrá que levantar entonces la interfaz virtual con IP 192.168.2.101 para que siga recibiendo peticiones de los clientes. En eso se basa la alta disponibilidad, en que el recurso esté disponible siempre para los clientes y cualquier problema de infraestructura se solucione de forma transparente, sin afectación de servicio.
Estos pasos que siguen sólo son necesarios en el nodo 1, ya que el servicio de mensajería de cluster corosync se encarga de avisar al resto de nodos cómo está parametrizado el clúster. Desactivamos stonith (utilizado para parar nodos problemáticos de un clúster de forma automática, en este caso no lo necesitamos):
crm configure property stonith-enabled=false
También desactivamos el quorum (sirve para determinar el nodo de clúster adecuado para retomar un servicio. En este caso sobra ya que ante la caída de un nodo, sólo queda el otro restante):
crm configure property no-quorum-policy=ignore
Añadimos la interfaz virtual en alta disponibilidad.
crm configure primitive FAILOVER-ADDR ocf:heartbeat:IPaddr2 params ip="192.168.2.101" nic="eth2:0" op monitor interval="10s" meta is-managed="true"
Comprobamos el estado del cluster con el comando crm_mon:
============ Last updated: Fri Mar 7 19:20:58 2014 Last change: Fri Mar 7 19:20:39 2014 via cibadmin on nodo1 Stack: openais Current DC: nodo1 - partition with quorum Version: 1.1.6-9971ebba4494012a93c03b40a2c58ec0eb60f50c 2 Nodes configured, 2 expected votes 1 Resources configured. ============ Online: [ nodo1 nodo2 ] FAILOVER-ADDR (ocf::heartbeat:IPaddr2): Started nodo1
Paramos el servicio corosync en el nodo 1:
service corosync stop
Y comprobamos el estado con crm_mon:
============ Last updated: Wed Mar 5 18:09:19 2014 Last change: Wed Mar 5 18:09:14 2014 via cibadmin on nodo2 Stack: openais Current DC: nodo2 - partition WITHOUT quorum Version: 1.1.6-9971ebba4494012a93c03b40a2c58ec0eb60f50c 2 Nodes configured, 2 expected votes 1 Resources configured. ============ Online: [ nodo2 ] OFFLINE: [ nodo1 ] FAILOVER-ADDR (ocf::heartbeat:IPaddr2): Started nodo2
¿Qué ha ocurrido? Pues que el nodo 2 ha levantado la interfaz virtual que inicialmente estaba en el nodo 1. Si haces ping a la IP 192.168.2.115 te responderá sin problemas.
Apache en alta disponibilidad
Añadimos el servicio de Apache:
crm configure primitive FAILOVER-APACHE lsb::apache2 op monitor interval=15s
Y para que esté todo ordenado, creamos un grupo de clúster:
crm configure group mi_cluster_web FAILOVER-ADDR FAILOVER-APACHE
Comprobamos con crm_mon:
============
Last updated: Wed Mar 5 20:56:32 2014
Last change: Fri Mar 7 23:08:07 2014 via cibadmin on nodo1
Stack: openais
Current DC: nodo2 - partition WITHOUT quorum
Version: 1.1.6-9971ebba4494012a93c03b40a2c58ec0eb60f50c
2 Nodes configured, 2 expected votes
2 Resources configured.
============
Online: [ nodo2 ]
OFFLINE: [ nodo1 ]
Resource Group: mi_cluster_web
FAILOVER-ADDR (ocf::heartbeat:IPaddr2): Started nodo2
FAILOVER-APACHE (lsb:apache2): Started nodo2
Y ya lo tenéis. Ahora si levantáis el nodo 1:
service corosync start
Y después tiráis el nodo 2 como hice anteriormente, veréis que el nodo 1 retoma los servicios de Apache y la Interfaz Virtual por la que sirve.