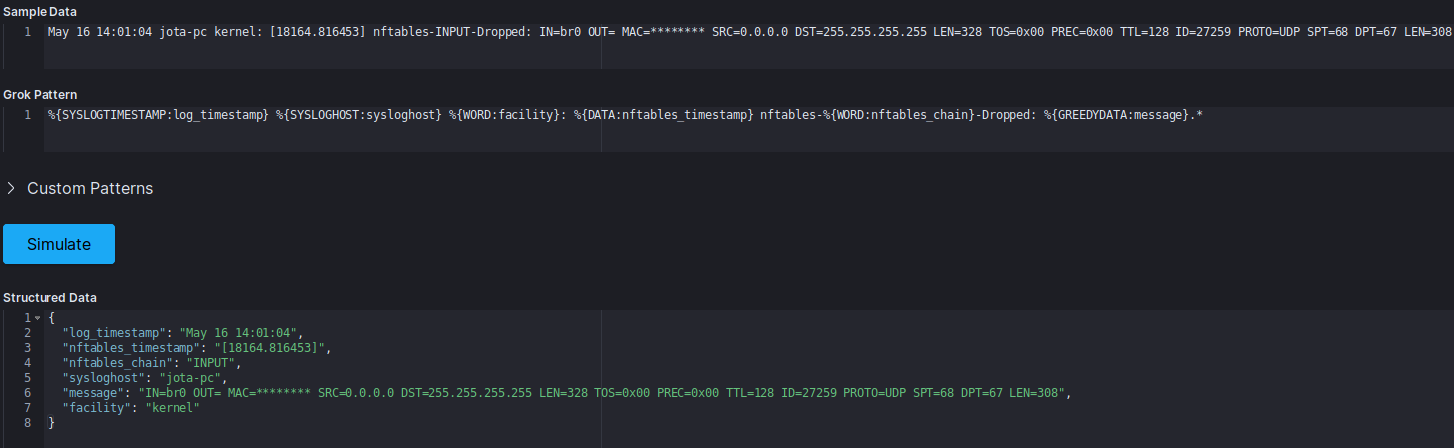
Ya llevo un tiempo almacenando logs de nftables en el stack ELK. Al principio guardando los mensajes tal cual llegaban y más tarde aplicando algunos filtros de logstash muy prácticos que me permiten tratar la información de una forma más amigable.
Los mensajes de log de nftables son de este tipo (la MAC está enmascarada)
May 16 14:01:04 jota-pc kernel: [18164.816453] nftables-INPUT-Dropped: IN=br0 OUT= MAC=******** SRC=0.0.0.0 DST=255.255.255.255 LEN=328 TOS=0x00 PREC=0x00 TTL=128 ID=27259 PROTO=UDP SPT=68 DPT=67 LEN=308
Sin aplicar ningún tipo de filtro en Logstash, los logs se indexan con esta estructura:
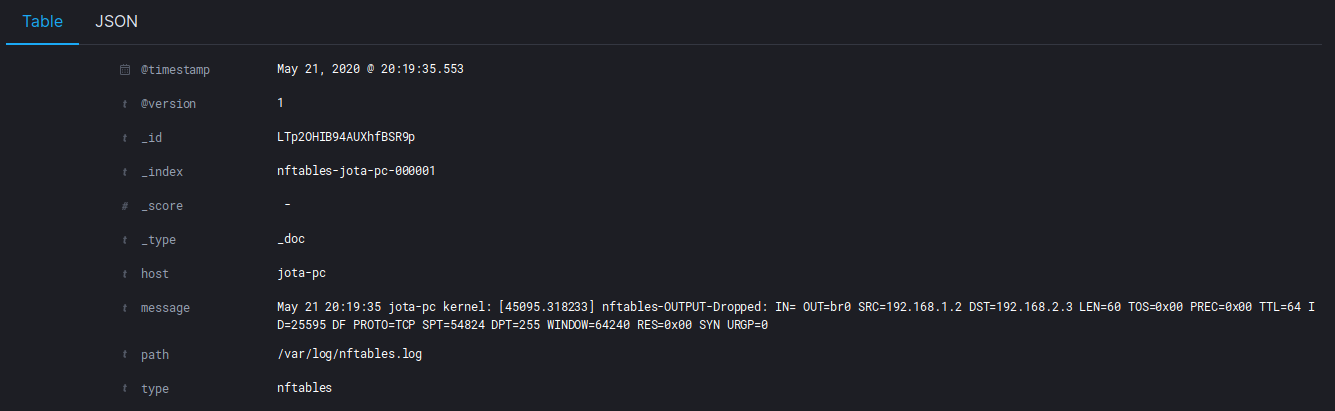
Esto se puede mejorar un poco:
- Elasticsearch ya añade un campo timestamp, así que podemos eliminar el que llega al principio del mensaje al ser redundante.
- El siguiente string
jota-pces el nombre del nodo de origen, podemos crear un campo nuevo donde almacenar esa información concreta. - El string
kerneles en realidad la facility de rsyslog encargada de generar el mensaje en el nodo remoto, podemos crear otro campo con esto. - Los valores numéricos entre corchetes
[45095.318233]son otro timestamp de rsyslog que puede eliminarse. - El string
nftables-OUTPUT-droppedes la cadena que ha denegado la conexión en nftables, en este caso OUTPUT. También lo podemos incluir en un campo adicional.
Visto lo anterior, en nuestra configuración de Logstash podemos aplicar dos filtros:
- Grok: para estructurar el mensaje como queremos.
- Mutate: para eliminar los campos que no necesitamos.
Quedando la configuración filter de esta manera:
filter {
grok {
match => [ "message", "%{SYSLOGTIMESTAMP:log_timestamp} %{SYSLOGHOST:sysloghost} %{WORD:facility}: %{DATA:nftables_timestamp} nftables-%{WORD:nftables_chain}-Dropped: %{GREEDYDATA:message}.*" ]
overwrite => [ "message" ]
}
mutate {
remove_field => [ "log_timestamp", "nftables_timestamp" ]
}
}
Tras aplicarlo, en Kibana podemos comprobar:
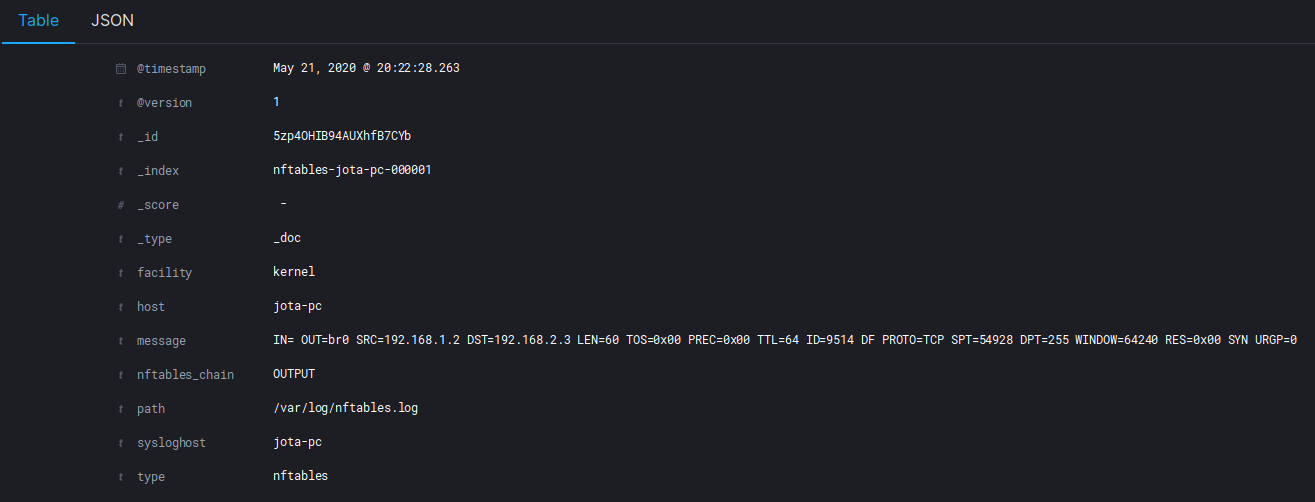
Ya tenemos los nuevos campos y hemos eliminado los que no eran relevantes.
A la hora de utilizar grok, resulta de gran ayuda el debugger que incorpora el propio Kibana en Dev Tools -> Grok Debugger. De esta manera podemos ver cómo se va a estructurar la información y no aplicar filtros a ciegas: